
What is a fiducial?
You may not have heard the word ‘fiducial’ before; outside the world of robotics (or electronics manufacture) it is little known. It refers to an easily-detected optical marker that is added to an object, so its position can be determined by an image-processing system.
It is similar to a 2-dimensional QR barcode, but has a much simpler structure, so can be detected at a distance; the tags in the photo above are only 12 mm (0.5 inch) in size, but I’ve successfully detected them in an HD image at a distance of 1.6 metres (over 5 feet).
The image analysis returns the x,y position of the tag centre, and the coordinates of its 4 corners, which can be used to highlight the tag outline in the camera image display; there is also a ‘goodness factor’ that indicates how well the tag has been matched; this can be used to filter out some spurious detections.
There isn’t just one type of fiducial; several organisations have developed their own formats. The type directly supported by OpenCV is known as ArUco, but I’ve opted for a rival system developed by the University of Michigan, called AprilTag. They have a full set of open-source software to generate & decode the tags; the decoder is written in C, with Python bindings, so can easily be integrated into a Raspberry Pi image processing system.
The AprilTag package has several tag ‘families’, that are characterised by two numbers; the number of data bits in a square, and the hamming distance between adjacent tags, e.g. 16h5 is a 4-by-4 data square, with a hamming distance of 5. The hamming distance is used to remove similar-looking tags that might easily be confused for each other, including rotations, so although 16h5 has 16 data bits, there are only 30 unique tags in that family.
I’m using 3 of the simpler families: 16h5, 25h9 and 36h11. Here are the tag values of 0 to 2 for each of them:

Generating Apriltag images
The original Apriltag generator here is written in Java, with the option of auto-generating C code. For simplicity, I’ve completely rewritten it in Python, with the option of outputting a bitmap (PNG/JPEG) or vector (SVG) file. The vector format allows us to generate tags with specific dimensions, that can accurately be reproduced by a low-cost laser printer.
To generate the tags, we need some ‘magic numbers’ that indicate which bits are set for a given tag. I got these numbers from the original Java code, for example Tag16h5.java has the lines:
public class Tag16h5 extends TagFamily
{
public Tag16h5()
{
super(16, 5, new long[] { 0x231bL, 0x2ea5L, 0x346aL etc..
}
}
I’ve copied the first 10 data entries from Tag16h5, 25h9 and 36h11 Java files:
tag16h5 = 16, 5,(0x231b,0x2ea5,0x346a,0x45b9,0x79a6,
0x7f6b,0xb358,0xe745,0xfe59,0x156d)
tag25h9 = 25, 9,(0x155cbf1,0x1e4d1b6,0x17b0b68,0x1eac9cd,0x12e14ce,
0x3548bb,0x7757e6,0x1065dab,0x1baa2e7,0xdea688)
tag36h11 = 36,11,(0xd5d628584,0xd97f18b49,0xdd280910e,0xe479e9c98,0xebcbca822,
0xf31dab3ac,0x056a5d085,0x10652e1d4,0x22b1dfead,0x265ad0472)
If you need more than 10 different tags of a given family, just copy more data values.
In my code, a tag is created as a 2-dimensional Numpy array, where ‘0’ is a black square, and ‘1’ is white. The source data is a right-justified bit-stream, for example the above value of 231b hex is decoded as follows:

There is a 1-bit solid black frame around the data bits, and an (invisible) 1-bit white frame round that. The encoder steps are:
- Calculate the number of data bits per row by taking the square root of the area
- Load the data for the required tag as an 8-byte big-endian value, convert it to a linear array of byte values
- Convert the byte array into bits, discard the unused left-most bits, and reshape into a square array
- Add a black (0) frame around the array
- Add a white (1) frame around the black frame
# Generate a tag with the given value, return a numpy array
def gen_tag(tag, val):
area, minham, codes = tag
side = int(math.sqrt(area))
d = np.frombuffer(np.array(codes[val], ">i8"), np.uint8)
bits = np.unpackbits(d)[-area:].reshape((-1,side))
bits = np.pad(bits, 1, 'constant', constant_values=0)
return np.pad(bits, 2, 'constant', constant_values=1)
We now have a numpy array with the desired binary pattern, that needs to be turned into a graphic.
Bitmap output
The extension on the output filename (.png, .jpg, .pgm, or .svg) determines the output file format. If a bitmap is required, Python Imaging Library (PIL, or the fork ‘pillow’) is used to convert the list of tag arrays into graphic objects. The binary bits only need to be multiplied by 255 to provide the full monochrome value, then are copied into the image. This creates one-pixel squares that are invisible without zooming, so the whole image is scaled up to a reasonable size.
# Save numpy arrays as a bitmap
def save_bitmap(fname, arrays):
img = Image.new('L', (IMG_WD,IMG_HT), WHITE)
for i,a in enumerate(arrays):
t = Image.fromarray(a * WHITE)
img.paste(t, (i*TAG_PITCH,0))
img = img.resize((IMG_WD*SCALE, IMG_HT*SCALE))
img.save(fname, FTYPE)
PGM output is an old uncompressed binary format, that is rarely encountered nowadays: it can be useful here because it is compatible with the standard apriltag_demo application, which I’ll be describing later.
Vector output
The vector (SVG) version uses the ‘svgwrite’ library, that can be installed using pip or pip3 as usual. The tag size is specified by setting the document and viewport sizes:
SCALE = 2
DWG_SIZE = "%umm"%(IMG_WD*SCALE),"%umm"%(IMG_HT*SCALE)
VIEW_BOX = "0 0 %u %s" % (IMG_WD, IMG_HT)
This means each square in the tag will be 2 x 2 mm, so 4 x 4 data bits plus a 1-bit black frame makes the visible tag size 12 x 12 mm.
The background is defined as white, so only the black squares need to be drawn; the numpy ‘where’ operator is used to return a list of bits that are zero.
# Save numpy arrays as a vector file
def save_vector(fname, arrays):
dwg = svgwrite.Drawing(fname, DWG_SIZE, viewBox=VIEW_BOX, debug=False)
for i,a in enumerate(arrays):
g = dwg.g(stroke='none', fill='black')
for dy,dx in np.column_stack(np.where(a == 0)):
g.add(dwg.rect((i*TAG_PITCH + dx, dy), (1, 1)))
dwg.add(g)
dwg.save(pretty=True)
Each tag is defined as a separate SVG group, which is convenient if it has to be copy-and-pasted into another image. If you are unfamiliar with SVG, take a look at my blog on the subject.
Source code for Apriltag generator
The source code (apriltag_gen.py) is compatible with Python 2.7 or 3.x, and can run on Windows or Linux. It requires numpy, svgwrite, and PIL/pillow to be installed using pip or pip3 as usual:
# Apriltag generator, from iosoft.blog
import sys, math, numpy as np, svgwrite
from PIL import Image
filename = 'test.svg' # Default filename (.svg, .png, .jpeg or .pgm)
family = 'tag16h5' # Default tag family (see tag_families)
NTAGS = 10 # Number of tags to create
TAG_PITCH = 10 # Spacing of tags
WHITE = 255 # White colour (0 is black)
# First 10 values of 3 tag families
tag16h5 = 16, 5,(0x231b,0x2ea5,0x346a,0x45b9,0x79a6,
0x7f6b,0xb358,0xe745,0xfe59,0x156d)
tag25h9 = 25, 9,(0x155cbf1,0x1e4d1b6,0x17b0b68,0x1eac9cd,0x12e14ce,
0x3548bb,0x7757e6,0x1065dab,0x1baa2e7,0xdea688)
tag36h11 = 36,11,(0xd5d628584,0xd97f18b49,0xdd280910e,0xe479e9c98,0xebcbca822,
0xf31dab3ac,0x056a5d085,0x10652e1d4,0x22b1dfead,0x265ad0472)
tag_families = {"tag16h5":tag16h5, "tag25h9":tag25h9, "tag36h11":tag36h11}
# Set up the graphics file, given filename and tag family
def set_graphics(fname, family):
global FTYPE, IMG_WD, IMG_HT, SCALE, DWG_SIZE, VIEW_BOX
FTYPE = fname.split('.')[-1].upper()
FTYPE = FTYPE.replace("PGM", "PPM").replace("JPG", "JPEG")
IMG_HT = int(math.sqrt(family[0])) + 6
IMG_WD = (NTAGS-1)*TAG_PITCH + IMG_HT
# Vector definitions
if FTYPE == "SVG":
SCALE = 2
DWG_SIZE = "%umm"%(IMG_WD*SCALE),"%umm"%(IMG_HT*SCALE)
VIEW_BOX = "0 0 %u %s" % (IMG_WD, IMG_HT)
# Bitmap definitions
else:
SCALE = 10
# Generate a tag with the given value, return a numpy array
def gen_tag(tag, val):
area, minham, codes = tag
dim = int(math.sqrt(area))
d = np.frombuffer(np.array(codes[val], ">i8"), np.uint8)
bits = np.unpackbits(d)[-area:].reshape((-1,dim))
bits = np.pad(bits, 1, 'constant', constant_values=0)
return np.pad(bits, 2, 'constant', constant_values=1)
# Save numpy arrays as a bitmap
def save_bitmap(fname, arrays):
img = Image.new('L', (IMG_WD,IMG_HT), WHITE)
for i,a in enumerate(arrays):
t = Image.fromarray(a * WHITE)
img.paste(t, (i*TAG_PITCH,0))
img = img.resize((IMG_WD*SCALE, IMG_HT*SCALE))
img.save(fname, FTYPE)
# Save numpy arrays as a vector file
def save_vector(fname, arrays):
dwg = svgwrite.Drawing(fname, DWG_SIZE, viewBox=VIEW_BOX, debug=False)
for i,a in enumerate(arrays):
g = dwg.g(stroke='none', fill='black')
for dy,dx in np.column_stack(np.where(a == 0)):
g.add(dwg.rect((i*TAG_PITCH + dx, dy), (1, 1)))
dwg.add(g)
dwg.save(pretty=True)
if __name__ == '__main__':
opt = None
for arg in sys.argv[1:]: # Process command-line arguments..
if arg[0]=="-":
opt = arg.lower()
else:
if opt == '-f': # '-f family': tag family
family = arg
else:
filename = arg # 'filename': graphics file
opt = None
if family not in tag_families:
print("Unknown tag family: '%s'" % family)
sys.exit(1)
tagdata = tag_families[family]
set_graphics(filename, tagdata)
print("Creating %s, file %s" % (family, filename))
tags = [gen_tag(tagdata, n) for n in range(0, NTAGS)]
if FTYPE == "SVG":
save_vector(filename, tags)
else:
save_bitmap(filename, tags)
Decoding Apriltags
For the decoder, I’m using the standard Apriltag ‘C’ code, which includes a Python library, so no knowledge of the C programming language is required. The code is Linux-specific, so will run on the Raspberry Pi, but not on Windows unless you install the Microsoft ‘Windows Subsystem for Linux’, which can compile & run the text-based decoder, but sadly not the graphical display.
On the raspberry pi, I’m using the Raspbian Buster distribution; the Apriltag build process may not be compatible with older distributions. I’ve had no success building on a Pi Zero, due to the RAM size being too small, so had to compile on a larger board, and transfer the files across.
The commands to fetch and compile the code are:
sudo apt install cmake cd ~ git clone https://github.com/AprilRobotics/apriltag cd apriltag cmake . make sudo make install make apriltag_demo
The installation command returns an error with the Python library, but succeeds in installing the other application files.
You can now run my Python tag encoder, and feed the output into the demonstration decoder supplied in the Apriltag package, for example:
python3 apriltag_gen.py -f tag16h5 test.jpg apriltag_demo -f tag16h5 test.jpg
You should be rewarded with a swathe of text, such as:
loading test.jpg detection 0: id (16x 5)-0 , hamming 0, margin 203.350 detection 1: id (16x 5)-1 , hamming 0, margin 246.072 detection 2: id (16x 5)-2 , hamming 0, margin 235.426 ..and so on..
The -0, -1, -2 sequence shows the decoded tag numbers, and the large ‘margin’ value indicates there is a high degree of confidence that the decode is correct. The time taken by the various decoder components is also displayed, which is useful if you’re trying to optimise the code.
If the decode fails, check that you’ve entered the tag family & filename correctly; the decoder application doesn’t accept JPEG files with a .jpeg extension, it has to be .jpg.
Python tag decoder
To use the Python library interface, you have to tell Python where to find the library file, for example at the command prompt:
export PYTHONPATH=${PYTHONPATH}:${HOME}/apriltag
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:${HOME}/apriltag/lib
This can be a bit of a nuisance; a quick (but rather inefficient) alternative is to copy the ‘.so’ library file from the compiled Apriltag package into the current directory. For my current build, the command would be:
cp ~/apriltag/apriltag.cpython-37m-arm-linux-gnueabihf.so .
You can now run a simple Python console program to exercise the library. It uses Python OpenCV, which needs to be installed using ‘apt’; see this blog for more information. File apriltag_decode.py:
# Simple test of Apriltag decoding from iosoft.blog
import cv2
from apriltag import apriltag
fname = 'test.jpg'
image = cv2.imread(fname, cv2.IMREAD_GRAYSCALE)
detector = apriltag("tag16h5")
dets = detector.detect(image)
for det in dets:
print("%s: %6.1f,%6.1f" % (det["id"], det["center"][0], det["center"][1]))
You will need to run this under python3, as the Apriltag library isn’t compatible with Python 2.x. The output is somewhat uninspiring, just showing the tag value, and the x & y positions of its centre, but is sufficient to show the decoder is working:
0: 49.9, 49.9 1: 149.9, 49.8 2: 249.9, 49.9 ..and so on..
Graphical display of detected tags
A better test is to take video from the Raspberry Pi camera, detect the value and position of the tags, and overlay that information onto the display. Here is the source code (apriltag_view.py):
# Detect Apriltag fiducials in Raspbery Pi camera image
# From iosoft.blog
import cv2
from apriltag import apriltag
TITLE = "apriltag_view" # Window title
TAG = "tag16h5" # Tag family
MIN_MARGIN = 10 # Filter value for tag detection
FONT = cv2.FONT_HERSHEY_SIMPLEX # Font for ID value
RED = 0,0,255 # Colour of ident & frame (BGR)
if __name__ == '__main__':
cam = cv2.VideoCapture(0)
detector = apriltag(TAG)
while cv2.waitKey(1) != 0x1b:
ret, img = cam.read()
greys = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dets = detector.detect(greys)
for det in dets:
if det["margin"] >= MIN_MARGIN:
rect = det["lb-rb-rt-lt"].astype(int).reshape((-1,1,2))
cv2.polylines(img, [rect], True, RED, 2)
ident = str(det["id"])
pos = det["center"].astype(int) + (-10,10)
cv2.putText(img, ident, tuple(pos), FONT, 1, RED, 2)
cv2.imshow(TITLE, img)
cv2.destroyAllWindows()
To test the code, create a tag16h5 file in SVG format:
python3 apriltag_gen.py -f tag16h5 test.svg
This vector file can be printed out using Inkscape, to provide an accurately-sized set of paper tags, or just displayed on the Raspberry Pi screen, by double-clicking in File Manager. Then run apriltag_view:
python3 apriltag_view.py
With the camera pointed at the screen, you can position the decoded images and original tags so they are both in view. Note that the camera doesn’t need to be at right-angles to the screen, the decoder can handle oblique images. The MIN_MARGIN value may need to be adjusted; it can be increased to suppress erroneous detections, but then some distorted tags may be missed.
To terminate the application, press the ESC key while the decoder display has focus.
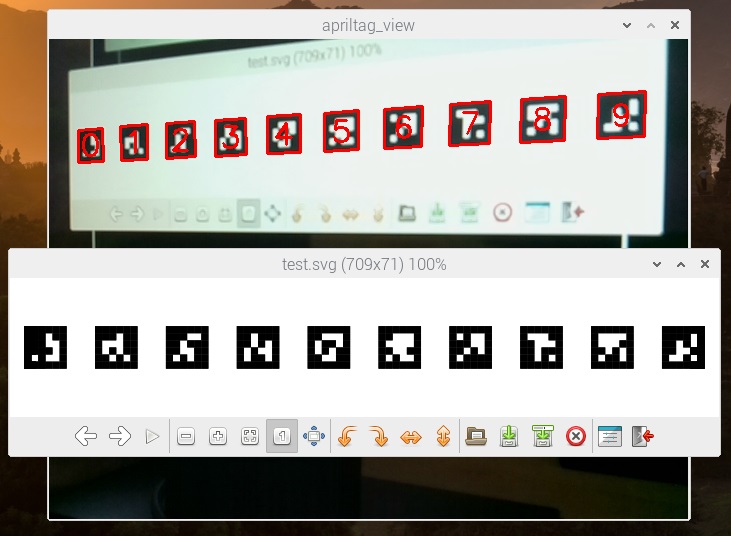
The application is a bit slower than I’d like, with a noticeable lag on the image display, so the code needs to be optimised.
Copyright (c) Jeremy P Bentham 2019. Please credit this blog if you use the information or software in it.




