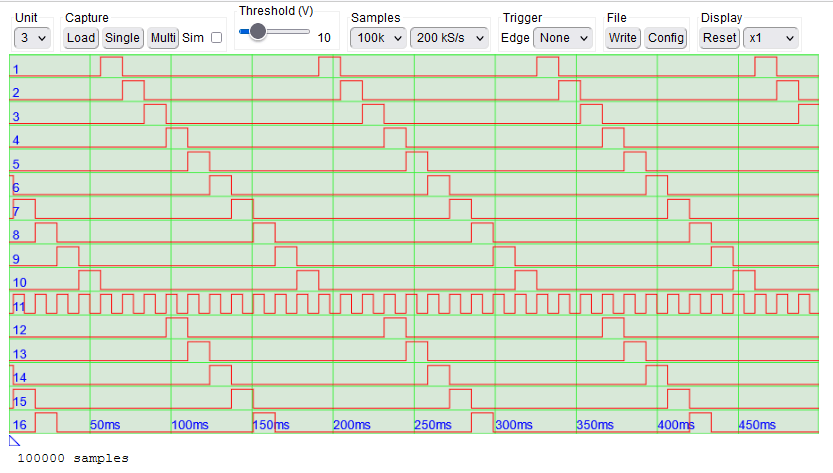
This is the third part of a 3-part blog post describing a low-cost WiFi-based logic analyser, that can be used for monitoring equipment in remote or hazardous locations. Part 1 described the hardware, part 2 the unit firmware, now this post describes the Web interface that controls the logic analyser units, and displays the captured data, also a Python class that can be used to remote-control the units for data analysis.
In a previous post, I experimented with shader hardware (via WebGL) for quickly displaying the logic analyser traces in a Web page. Whilst this technique can provide really fast display updates, there were some browser compatibility problems, and also a pure-javascript version proved to be fast enough, given that the main constraint is the time taken to transfer the data over the network.
So the current solution just used HTML and Javascript, with no hardware acceleration.
Network topology
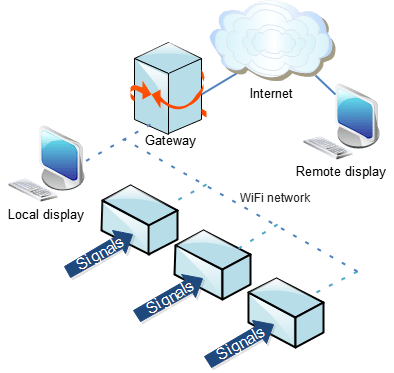
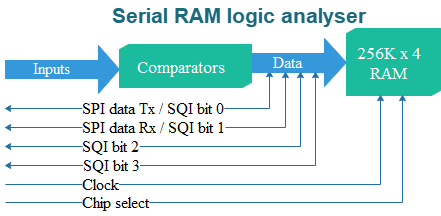
In part 2, I described how the analyser units return data in response to Web page requests; the status information is in the form of a JSON string, and the sample data is Base64 encoded. So each unit has a built-in Web server, and it is tempting to load the HTML display files onto them. However, I chose not to do that, for the following reasons:
- The analyser units use microcontrollers with finite resources, and not much spare storage space.
- Every time the display software is updated, it would have to be loaded onto all the units individually.
- It is easier to keep a single central server up-to-date with all the necessary security & access control measures.
So I’m assuming that there is a Web server somewhere on the system that serves the display file, and any necessary library files. This is a bit inconvenient for development, so when debugging I run a Web server on my development PC, for example using Python 3:
python -m http.server 8000
This launches a server on port 8000; if the display file is in a subdirectory ‘test’, its URL would look like:
http://127.0.0.1:8000/test/remla.html
There is also a question how the display program knows the addresses of the units, so it can access the right one. I had intended to use Multicast DNS (MDNS) for this purpose, but it proved to be a bit unreliable, so I assigned static IP addresses to the units instead.
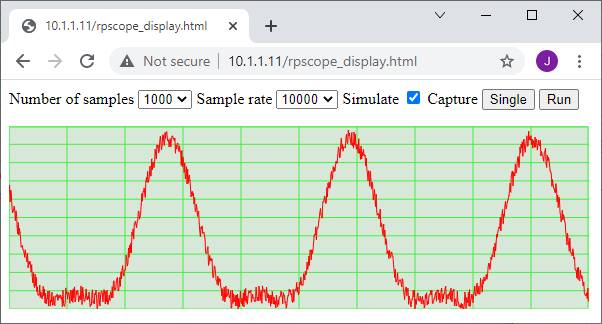
Data display
The waveforms are drawn as vectors (as opposed to bitmaps), so the display can be re-sized to suit any size of screen. There are two basic drawing methods that can be used: an HTML canvas, or SVG (Scalable Vector Graphics). After some experimentation, I adopted the former, as it seemed to be a more flexible solution; the canvas is just an area of the screen that responds to simple line- and text-drawing commands, for example to draw & label the display grid:
var ctx1 = document.getElementById("canvas1").getContext("2d");
drawGrid(ctx1);
// Draw grid in display area
function drawGrid(ctx) {
var w=ctx.canvas.clientWidth, h=ctx.canvas.clientHeight;
var dw = w/xdivisions, dh=h/ydivisions;
ctx.fillStyle = grid_bg;
ctx.fillRect(0, 0, w, h);
ctx.lineWidth = 1;
ctx.strokeStyle = grid_fg;
ctx.strokeRect(0, 1, w-1, h-1);
ctx.beginPath();
for (var n=0; n<xdivisions; n++) {
var x = n*dw;
ctx.moveTo(x, 0);
ctx.lineTo(x, h);
ctx.fillStyle = 'blue';
if (n)
drawXLabel(ctx, x, h-5);
}
for (var n=0; n<ydivisions; n++) {
var y = n*dh;
ctx.moveTo(0, y);
ctx.lineTo(w, y);
}
ctx.stroke();
}
Drawing the logic traces uses a similar method; begin a path, add line drawing commands to it, then invoke the stroke method.
Controls
The various control buttons and list boxes need to be part of a form, to simplify the process of sending their values to the analyser unit. So they are implemented as pure HTML:
<form id="captureForm">
<fieldset><legend>Unit</legend>
<select name="unit" id="unit" onchange="unitChange()">
<option value=1>1</option><option value=2>2</option><option value=3>3</option>
<option value=4>4</option><option value=5>5</option><option value=6>6</option>
</select>
</fieldset>
<fieldset><legend>Capture</legend>
<button id="load" onclick="doLoad()">Load</button>
<button id="single" onclick="doSingle()">Single</button>
<button id="multi" onclick="doMulti()">Multi</button>
<label for="simulate">Sim</label>
<input type="checkbox" id="simulate" name="simulate">
</fieldset>
..and so on..
To update the parameters on the unit, they are gathered from the form, and sent along with an optional command, e.g. cmd=1 to start a capture.
// Get form parameters
function formParams(cmd) {
var formdata = new FormData(document.getElementById("captureForm"));
var params = [];
for (var entry of formdata.entries()) {
params.push(entry[0]+ '=' + entry[1]);
}
if (cmd != null)
params.push("cmd=" + cmd);
return params;
}
// Get status from unit, optionally send command
function get_status(cmd=null) {
http_request = new XMLHttpRequest();
http_request.addEventListener("load", status_handler);
http_request.addEventListener("error", status_fail);
http_request.addEventListener("timeout", status_fail);
var params = formParams(cmd), statusfile=remote_ip()+'/'+statusname;
http_request.open( "GET", statusfile + "?" + encodeURI(params.join("&")));
http_request.timeout = 2000;
http_request.send();
}
The result of this HTTP request is handled by callbacks, for example if the request fails, there is a retry mechanism:
// Handle failure to fetch status page
function status_fail(e) {
var evt = e || event;
evt.preventDefault();
if (retry_count < RETRIES) {
addStatus(retry_count ? "." : " RETRYING")
get_status();
retry_count++;
}
else {
doStop();
redraw(ctx1);
}
}
This mechanism was found to be necessary since very occasionally the remote unit fails to respond, for no apparent reason; if there is a real reason (e.g. it has been powered down) then the transfer is halted after 3 attempts.
If the status information has been returned OK, then a suitable action is taken; if a capture has been triggered, and the status page indicates that the capture is complete, then the data is fetched:
// Decode status response
function status_handler(e) {
var evt = e || event;
var remote_status = JSON.parse(evt.target.responseText);
var state = remote_status.state;
if (state != last_state) {
dispStatus(state_strs[state]);
last_state = state;
}
addStatus(".");
if (state==STATE_IDLE || state==STATE_PRELOAD || state==STATE_PRETRIG || state==STATE_POSTTRIG) {
repeat_timer = setTimeout(get_status, 500);
}
else if (remote_status.state == STATE_READY) {
loadData();
}
else {
doStop();
}
}
Fetching data
Fetching the data is similar to fetching the status page, since it is a text file containing base64-encoded bytes. The callback converts the text into bytes, then pairs of bytes into an array of numeric values:
// Read captured data (display is done by callback)
function loadData() {
dispStatus("Reading from " + remote_ip());
http_request = new XMLHttpRequest();
http_request.addEventListener("progress", capfile_progress_handler);
http_request.addEventListener( "load", capfile_load_handler);
var params = formParams(), capfile=remote_ip()+'/'+capname;
http_request.open( "GET", capfile + "?" + encodeURI(params.join("&")));
http_request.send();
}
// Display data (from callback event)
function capfile_load_handler(event) {
sampledata = getData(event.target.responseText);
doZoomReset();
if (command == CMD_MULTI)
window.requestAnimationFrame(doStart);
else
doStop();
}
// Get data from HTTP response
function getData(resp) {
var d = resp.replaceAll("\n", "");
return strbin16(atob(d));
}
// Convert string of 16-bit values to binary array
function strbin16(s) {
var vals = [];
for (var n=0; n<s.length;) {
var v = s.charCodeAt(n++);
vals.push(v | s.charCodeAt(n++) << 8);
}
return vals;
}
It is probable that this process could be streamlined somewhat, but currently the main speed restriction is the transfer of data from the ESP to the PC over the wireless network, so improving the byte-decoder wouldn’t give a noticeable speed improvement.
Saving the data
There needs to be some way of saving the sample data for further analysis; as it happens, the initial users of the system were already using the open-source Sigrok Pulseview utility for capturing data from small USB pods, so it was decided to save the data in the Sigrok file format.
This a basically a zipfile, with 3 components:
- Metadata, identifying the channels, sample rate, etc.
- Version, giving the file format version (currently 2)
- Logic file, containing the binary data
The metadata format is quite easy to replicate, e.g.
[global]
sigrok version=0.5.1
[device 1]
capturefile=logic-1
total probes=16
samplerate=5 MHz
total analog=0
probe1=D1
probe2=D2
probe3=D3
..and so on until..
probe16=D16
unitsize=2
The dummy labels D1, D2 etc. are normally replaced with meaningful descriptions of the signals, followed by the unitsize parameter which gives the byte-width of the data, and marks the end of the labels.
The JSZip library is used to zip the various components together in a single file with the ‘sr’ extension:
function write_srdata(fname) {
var meta = encodeMeta(), zip = new JSZip();
var samps = new Uint16Array(sampledata);
zip.file("metadata", meta);
zip.file("version", "2");
zip.file("logic-1-1", samps.buffer);
zip.generateAsync({type:"blob", compression:"DEFLATE"})
.then(function(content) {
writeFile(fname, "application/zip", content);
});
}
// Encode Sigrok metadata
function encodeMeta() {
var meta=[], rate=elem("xrate").value + " Hz";
for (var key in sr_dict) {
var val = key=="samplerate" ? rate : sr_dict[key];
meta.push(val[0]=='[' ? ((meta.length ? "\n" : "") + val) : key+'='+val);
}
for (var n=0; n<nchans; n++) {
meta.push("probe"+(n+1) + "=" + (probes.length?probes[n]:n+1));
}
meta.push("unitsize=2");
return meta.join("\n");
}
Configuration
So far, the only way the units can be configured is by using the browser controls, to set the sample rate, number of samples, threshold etc. Whilst this might be acceptable for a portable system, a semi-permanent installation needs some way of storing the configuration, including the naming of input channels on the display. Since there is a central Web server for the display files, can’t this also be used to store configuration files? The answer is ‘yes’, but there is then a question how these files can be modified in a browser-friendly way.
This is a bit difficult, since there are numerous security protections for the files on a server, to make sure they can’t be modified by a Web client. However, there is an extension to the HTTP protocol known as WebDAV (Web Distributed Authoring and Versioning), which does provide a mechanism for writing to files. Basically you need a general-purpose Web server that can be configured to support Web DAV (such as lighttpd, see this page), or alternatively a special-purpose server, such as wsgidav (see this page).
Assuming you already have a working lighttpd server, the additional configuration file may look something like this, with some_path, dav_username and dav_password being customised for your installation:
File lighttpd/conf.d/30-webdav.conf:
server.modules += ( "mod_webdav" )
$HTTP["url"] =~ "^/dav($|/)" {
webdav.activate = "enable"
webdav.sqlite-db-name = "/some_path/webdav.db"
server.document-root = "/www/"
auth.backend = "plain"
auth.backend.plain.userfile = "/some_path/webdav.shadow"
auth.require = ("" => ("method" => "basic", "realm" => "webdav", "require" => "valid-user"))
}
File /some_path/webdav.shadow
dav_username:dav_password
Create directory www/dav for files
Instead, you can use wsgidav to act as a Web and DAV server, run using the Windows command line:
wsgidav.exe --host 0.0.0.0 --port=8000 -c wsgidav.json
The JSON-format configuration file I’m using is:
{
"host": "0.0.0.0",
"port": 8080,
"verbose": 3,
"provider_mapping": {
"/": "/projects/remla/test",
"/test": "/projects/remla/test",
},
"http_authenticator": {
"domain_controller": null,
"accept_basic": true,
"accept_digest": true,
"default_to_digest": true,
"trusted_auth_header": null
},
"simple_dc": {
"user_mapping": {
"*": {
"dav_username": {
"password": "dav_password"
}
}
}
},
"dir_browser": {
"enable": true,
"response_trailer": "",
"davmount": true,
"davmount_links": false,
"ms_sharepoint_support": true,
"htdocs_path": null
}
}
Again, this will need to be customised for your environment, and you also need to be mindful that the configurations I’ve shown for lighttpd and wsgidav are quite insecure, for example the password isn’t encrypted, so it can easily be captured by anyone snooping on network traffic.
Configuration Web page
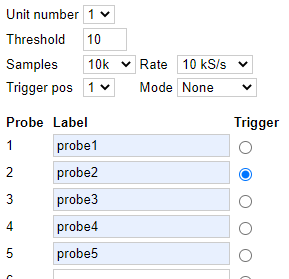
I created a simple Web page to handle the configuration, with list boxes for most options, and text boxes to allow the input channels to be named.
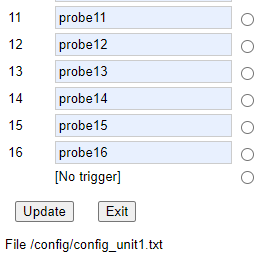
At the bottom of the page there are buttons to submit the new configuration to the server, and exit back to the waveform display page.
The key Javascript function to save the configuration on the server uses the ‘davclient’ library, and is quite simple, but it does need to know the host IP address and port number to receive the data. This code attempts to fetch that information using the DOM Location object:
// Save the config file
function saveConfig() {
var fname = CONFIG_UNIT.replace('$', String(unitNum()));
var ip = location.host.split(':')
var host = ip[0], port = ip[1];
port = !port ? 80 : parseInt(port);
var davclient = new davlib.DavClient();
davclient.initialize(host, port, 'http', DAVUSER, DAVPASS);
davclient.PUT(fname, JSON.stringify(getFormData()), saveHandler)
}
For simplicity, the DAV username and password are stored as plain text in the Javascript, which means that anyone viewing the page source can see what they are. This makes the server completely insecure, and must be improved.
Python interface
Although some data analysis can be done in Javascript, it is much more convenient to use Python and its numerical library numpy. I have written a Python class EdlaUnit that provides an API for remote control and data analysis, and a program edla_sweep that demonstrates this functionality.
It repeatedly captures a data block, whilst stepping up the threshold voltage. Then for each block, the number of transitions for each channel is counted and displayed.
import edla_utils as edla, base64, numpy as np
edla.verbose_mode(False)
unit = edla.EdlaUnit(1, "192.168.8")
unit.set_sample_rate(10000)
unit.set_sample_count(10000)
MIN_V, MAX_V, STEP_V = 0, 50, 5
def get_data():
ok = False
data = None
status = unit.fetch_status()
if status:
ok = unit.do_capture()
else:
print("Can't fetch status from %s" % unit.status_url)
if ok:
data = unit.do_load()
if data == None:
print("Can't load data")
return data
for v in range(MIN_V, MAX_V, STEP_V):
unit.set_threshold(v)
d = get_data()
byts = base64.b64decode(d)
samps = np.frombuffer(byts, dtype=np.uint16)
diffs = np.diff(samps)
edges = np.where(diffs != 0)[0]
totals = np.zeros(16, dtype=int)
for edge in edges:
bits = samps[edge] ^ samps[edge+1]
for n in range(0, 15):
if bits & (1<<n):
totals[n] += 1
s = "%4u," % v
s += ",".join([("%4u" % val) for val in totals])
print(s)
The idea is to give a quick overview of the logic levels the analyser is seeing, to make sure they are within reasonable bounds. An example output is:
Volts Ch1 Ch2 Ch3 Ch4 Ch5 Ch6 Ch7 Ch8
0, 0, 0, 0, 0, 0, 0, 0, 0
5, 564, 384, 620, 454, 548, 550, 572, 552
10, 328, 286, 326, 288, 302, 318, 326, 314
15, 260, 246, 262, 244, 260, 254, 260, 250
20, 216, 192, 216, 198, 202, 202, 208, 206
25, 92, 0, 122, 0, 60, 30, 106, 44
30, 0, 0, 0, 0, 0, 0, 0, 0
35, 0, 0, 0, 0, 0, 0, 0, 0
40, 0, 0, 0, 0, 0, 0, 0, 0
45, 0, 0, 0, 0, 0, 0, 0, 0
The absolute count isn’t necessarily very important, since it will vary depending on the signal that is being monitored. What is interesting is the way it changes as the threshold voltage increases. If the number dramatically increases as the ‘1’ logic voltage is approached, one might suspect that there is a noise problem, causing spurious edges. Conversely, if the value declines rapidly before the ‘1’ voltage is reached, the logic level is probably too low.
There is a tendency to assume that all logic signals are a perfect ‘1’ or ‘0’, with nothing in between; this technique allows you to look beyond that, and check whether your signals really are that perfect – and of course you can use the power of Python and numpy to do other analytical tests, or protocol decoding, specific to the signals being monitored.
—
Part 1 of this project looked at the hardware, part 2 the ESP32 firmware. The source files are on Github.
Copyright (c) Jeremy P Bentham 2022. Please credit this blog if you use the information or software in it.