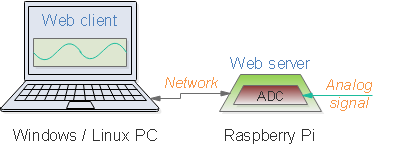
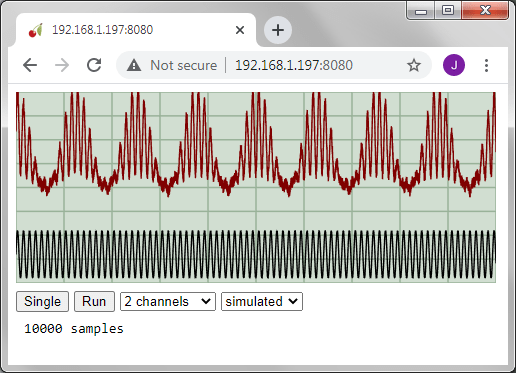
In a previous post, I used hardware-accelerated graphics to display oscilloscope waveforms in a browser; the next step is to plot logic waveforms, as would normally be displayed on a logic analyser.
We could potentially use exactly the same techniques as before, but this becomes quite inefficient when displaying a large number of logic channels. A real-time display needs a fast redraw-rate, which means maximising the work done by the Graphics Processor (GPU), since it can perform parallel calculations much faster than the Central Processor (CPU), even when running on a low-cost PC, tablet or mobile phone.
Looking at the above graphic, you can see that a major computation step is converting each 16-bit sample value into 16 ‘high’ or ‘low’ trace values. The trace has 20,000 samples, so 320,000 such calculations are needed, which is still quite do-able on the CPU, but it is not unusual for the sample count to be a million or more, which can result in a very sluggish display, making it difficult to scroll through the data, when looking for a specific data pattern.
Fortunately WebGL version 2 supports a technique called ‘instanced rendering’, which we can use to generate 16 or more trace values from a single data word. So we can feed the GPU with a block of raw sample data, and it will split that word into bits, and draw the appropriate vectors on the display, applying the necessary scaling, offsets and colouring.
Shader programming
Graphics Processor (GPU) programming is generally known as shader programming because the main computational elements are the ‘vertex’ and ‘fragment’ shaders, that take in a stream of data, and output a stream of pixels.

To optimise the shader operation, all the attributes for all the lines are usually stored in a single buffer, which is passed to the shaders as a single block; this allows the shaders to work at maximum speed, without having to interact with the main CPU.
In addition to this data, there are ‘uniform’ variables, that allow slowly-changing data values to be passed from the CPU to the GPU, for example specifying the scale, offset and colour of the individual traces.
Instanced rendering
Traditionally there is a one-to-one relationship between the incoming vertex attributes, and an object plotted on the screen; for example, the attributes may specify a line in 3 dimensions (2 points, each with z, y and z dimensions) and the shaders will draw that line on the display, by colouring in the necessary pixels.
Instanced rendering (in WebGL v2) allows a single set of vertex attributes to generate several copies (‘instances’) of an object. For example, one set of attributes can generate 100 identical objects, which is much more efficient than using adding 100 sets of attributes to the buffer.
At first sight, it is difficult to understand how this can be of use; the instances share the same coordinate values, so won’t they all be plotted on top of each other? The answer is yes, they will all be at the same location, unless we use the ‘instance number’ provided by the shader to space them out. So if I’m creating 16 instances from one sample value, they will be numbered 0 to 15. This allows me to assign a specific y-value to each instance, ensuring they are stacked in the display without overlap – and I can also use the instance number as a mask to select the appropriate bit-value to be plotted:
// Simplified vertex shader code
// Array with input data
in float a_data;
// Array with y scale & offset values
uniform vec2 u_scoffs[MAX_CHANS];
// Number of data points
uniform int u_npoints;
// Main shader operation
void main(void) {
// Convert sample value from float to integer
int d = int(a_data);
// Get data bit for this instance (this trace)
bool hi = (d & (1<<gl_InstanceID)) != 0;
// Get x-position from vertex num, normalised to +/- 1.0
float x = float(gl_VertexID) * (2.0/float(u_npoints)) - 1.0;
// Get y-position from scale & offset array
float y = u_scoffs[gl_InstanceID][1];
// Adjust y-value if bit is high
if (hi)
y += u_scoffs[gl_InstanceID][0];
// Set xyz position of this point
gl_Position = vec4(x, y, 0, 1);
// Set colour of this point (red if high)
v_colour = hi ? vec4(0.8, 0.2, 0.2, 1.0) : vec4(0.3, 0.3, 0.3, 1.0);
}
A notable feature is that I’ve specified the input data as being 32-bit floating-point numbers, when the incoming data samples are really 16-bit integers. This is because I had difficulty in persuading the shader code to compile with 16 or 32-bit integer inputs; only floating-point numbers seem to be acceptable for the vertex attributes. There is evidence on the Web to suggest that this is a feature of the shader hardware, and not a shortcoming of the compiler, but regardless of the reason, I’m doing the conversion to and from floating-point values, until I can be sure that integer attributes won’t cause problems.
The Javascript command to draw the traces is:
gl.clear(gl.COLOR_BUFFER_BIT);
gl.drawArraysInstanced(gl.LINE_STRIP, 0, trace_data.length, num_traces);
The lines are plotted in ‘strip’ mode, so plotting 20,000 line segments requires 20,001 coordinate points, as the end of one line segment is the same as the start of the next line. This has the consequence of making all the rising and falling edges non-vertical, as seen below.

This display is highly unconventional; logic analysers normally only draw vertical & horizontal lines. However, I quite like this feature, since it acts as a reminder of the limitations due to the sample rate; if a pulse is shown as a triangle, it only changed state for one sample-period.
Canvasses
We need a way of adding annotation to the WebGL display, for example the trace identification boxes on the left-hand side. It is possible to draw these using WebGL, but the process is a bit complex; it is much easier to just overlay a second canvas with a 2D rendering context, and use that API to superimpose lines & text onto the WebGL image, e.g.
<style>
.container {
position: relative;
}
#graph_canvas {
position: relative;
left: 0; top: 0; z-index: 1;
}
#text_canvas {
position: absolute;
left: 0; top: 0; z-index: 10;
}
</style></head>
<body>
<div class="container">
<canvas id="graph_canvas"></canvas>
<canvas id="text_canvas"></canvas>
</div>
</body>
The text canvas will remain transparent until we draw on it, for example:
// Get 2D context
var text_ctx = text_canvas.getContext("2d");
// Clear the text canvas
function text_clear() {
text_ctx.clearRect(0, 0, text_ctx.canvas.width, text_ctx.canvas.height);
}
// Draw a text box, given bottom-left corner & size
function text_box(x, y, w, h, txt) {
text_ctx.font = h + 'px sans-serif';
text_ctx.beginPath();
text_ctx.textBaseline = "bottom";
text_ctx.rect(x-1, y-h-1, w+2, h);
text_ctx.stroke();
text_ctx.fillText(txt, x, y, w);
}
Zoom
An analyser trace may have a million or more 16-bit samples, so we need the ability to magnify an area of interest. In theory I could extract the relevant section of the data, and feed it to the shader as a smaller buffer, but the main thrust of this project is to let the shader do all the hard work, so I always give it the full set of samples, and a two ‘uniform’ variables are used to specify an offset into the data, and the number of samples to be displayed.
bool hi = (d & (1<<gl_InstanceID)) != 0;
float x = float(gl_VertexID-u_disp_oset) * (2.0/float(u_disp_nsamp)) - 1.0;
float y = u_scoffs[gl_InstanceID][1];
if (hi)
y += u_scoffs[gl_InstanceID][0];
gl_Position = vec4(x, y, 0, 1);
To calculate the x-position, the VertexID is used, which is an incrementing counter that keeps track of how many samples have been processed; this is combined with disp_oset and disp_nsamp which are the offset (in samples) of the start of the data to be displayed, and the number of samples to be displayed. The resulting x-value is normalised, i.e. scaled to within -1.0 and +1.0 for all the pixels that should be displayed; any pixels outside that range will be suppressed.
The y-position of a ‘0’ bit is derived from the offset array for each channel; for a ‘1’ bit, a scale value is added on. This allows the main Javascript code to control the position & amplitude of each trace, ensuring they don’t overlap.

Number of channels
I’ve imposed an arbitrary maximum of 16 channels (i.e. 16 traces in the display); the GPU is capable of plotting many more than that, but there is a limitation due to the fact that we’re sending floating-point values to the vertex shader; this has a 24-bit mantissa, so if we feed in values with 24 or more bits, there is the risk that the floating-point value will be an approximation of the sample data, which is useless for this application, since the precise value of each bit is important. So take care when increasing the number of channels beyond 16; make sure the data being plotted is the same as the data being gathered.
The web page includes selection boxes to set the number of channels, and zoom level. The Javascript code automatically adjusts the scale & offset values for each channel; you can resize the window to anything convenient, and they will automatically fill the given canvas size.

Browser compatibility
The code should run on relatively modern browsers that support WebGL v2, regardless of operating system; I have had success running Chrome 87 and Firefox 61 on Windows 7 & 10, Linux and Android.
With regard to Apple products, older browsers such as Safari 10 don’t work at all, and I’ve had no success with an iPhone 8. However, Safari 14 does work if you specifically enable WebGL 2 in the developer ‘experimental features’, and Chrome on a Macbook Pro runs fine.
Running the code
There is a single HTML file webgl_logic.html, which has all the page formatting, Javascript, and GLSL v2 shader code; it is available on Github here.
When loaded into a suitable browser, it will display 16 waveforms, representing 20,000 samples with a 16-bit binary value incrementing from zero. The display can be animated once by clicking ‘single’, or continuously using ‘run’. You can adjust the zoom level at any time by clicking the selection box, or pressing ‘+’ or ‘-‘ on the keyboard. The offset of the zoomed area is modified by clicking on the display area, then using the left and right-arrow keys.
To experiment with larger data sets, you can increase the NSAMP value in the Javascript code. Don’t forget that by default every data sample generates 16 traces, so 1 million samples means the GPU will be generating 16 million vectors; the speed with which it can do this will depend on the specification of your hardware, and size of the display window, but you can get reasonable performance on a typical office PC; an expensive graphics card isn’t necessary.
Copyright (c) Jeremy P Bentham 2021. Please credit this blog if you use the information or software in it.